5-3 activation#
Activation function plays a key role in deep learning. It introduces the nonlinearity that enables the neural network to fit arbitrary complicated functions.
The neural network, no matter how complicated the structure is, is still a linear transformation which cannot fit the nonlinear functions without the activation function.
For the time being, the most popular activation function is relu, but there are some new functions such as swish, GELU, claiming a better performance over relu.
Here are two review papers to the activation function (in Chinese).
1. The most popular activation functions#
tf.nn.sigmoid: Compressing real number between 0 to 1, usually used in the output layer for binary classification; the main drawbacks are vanishing gradient, high computing complexity, and the non-zero center of the output.
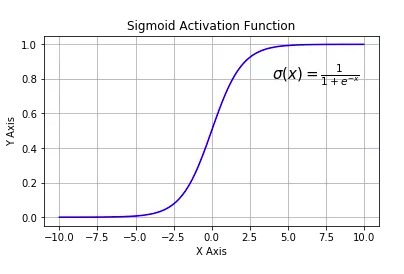
tf.nn.softmax: Extended version of sigmoid for multiple categories, usually used in the output layer for multiple classifications.
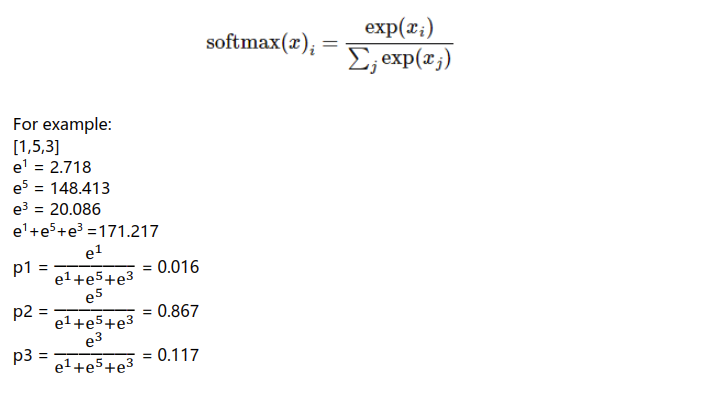
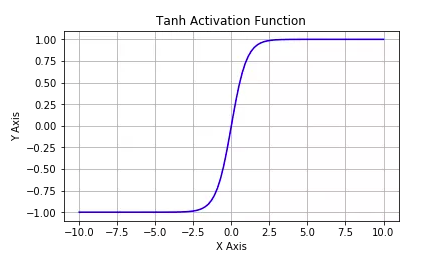
tf.nn.tanh:Compressing real number between -1 to 1, expectation of the output is zero; the main drawbacks are vanishing gradient and high computing complexity.
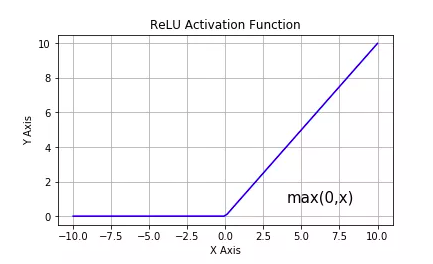
tf.nn.relu:Linear rectified unit, the most popular activation function, usually used in the hidden layer; the main drawbacks are non-zero center of the output and vanishing gradient for the inputs < 0 (dying relu).
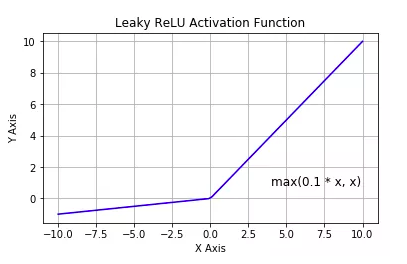
tf.nn.leaky_relu:Improved ReLU, resolving the dying ReLU problem.
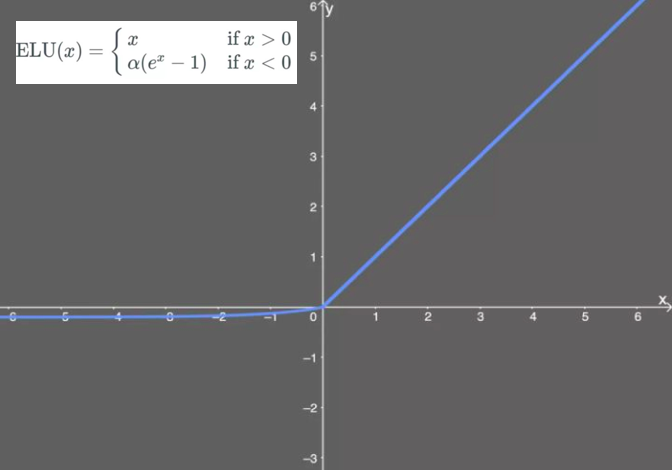
tf.nn.elu:Exponential linear unit, which is an improvement to the ReLU, alleviate the dying ReLU problem.
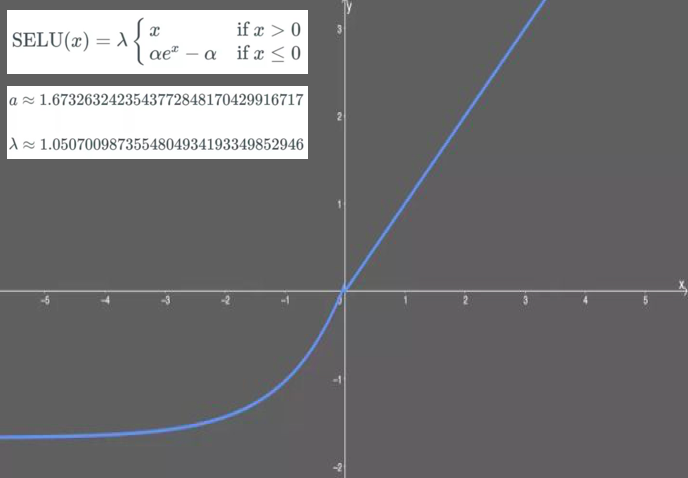
tf.nn.selu:Scaled exponential linear unit, which is able to normalize the neural network automatically if the weights are initialized throughtf.keras.initializers.lecun_normal. No gradient exploding/vanishing problems, but need to apply together with AlphaDropout (an alternation of Dropout).
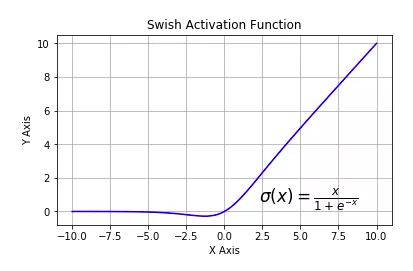
tf.nn.swish:Self-gated activation function, a research product form Google. The literature prove that it brings slight improvement comparing to ReLU.
gelu:Gaussian error linear unit, which has the best performance in Transformer; howevertf.nnhasn't implemented it.
2. Implementing activation functions in the models#
There are two ways of implementing activation functions in Keras models: specifying through the activation parameter in certain layers, or adding activation layer layers.Activation explicitly.
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras import layers,models
tf.keras.backend.clear_session()
model = models.Sequential()
model.add(layers.Dense(32,input_shape = (None,16),activation = tf.nn.relu)) # Specifying through the activation parameter
model.add(layers.Dense(10))
model.add(layers.Activation(tf.nn.softmax)) # adding `layers.Activation` explicitly.
model.summary()
Please leave comments in the WeChat official account "Python与算法之美" (Elegance of Python and Algorithms) if you want to communicate with the author about the content. The author will try best to reply given the limited time available.
You are also welcomed to join the group chat with the other readers through replying 加群 (join group) in the WeChat official account.
