5-6 metrics#
Besides being used as optimization target during training, loss function also acts as an evaluation remark of model performance. However, in general, the performance of the model is evaluated using other terms.
This is evaluation metrics. Loss function could be used as metrics. MAE, MSE, CategoricalCrossentropy are several most common metrics.
However, metrics is not necessarily able to act as loss function, such as AUC, Accuracy, Precision. This is because metrics is not required to be continuously differentiable, while this is a general requirement for the loss function.
Multiple metrics could be specified through list during the compilation of the model.
Metrics could be customized if necessary.
The customzed metrics requires two tensors y_true and y_pred as input,and it output a scalar as the value of the caluclated metrics.
It is also possible to customize metrics through inheriting from the base class tf.keras.metrics.Metric and rewrite the init, update_state, and result methods to implement the calculation of metrics.
Usually the training are performed batch by batch, while metrics could be calculated only after a whole epoch, thus the class-type metrics is more popular. We need to write initialization method to create the necessary middle variables (they are related to the resulting metrics), write the update_state method to update the states of these middle variables after each batch, and write the result method for the final output.
If the metrics is written as a function, it is only possible to use the avaraged metrics among all the batches in the epoch as the overal metrics. This usually deviates from the result calculated by all training steps in the epoch.
1. Most Frequently Used Pre-defined Metrics#
-
MeanSquaredError (Mean Squared Error, used for regression, dubbed as "MSE", function name
mse) -
MeanAbsoluteError (Mean Absolute Error, used for regression, dubbed as "MAE", function name
mae) -
MeanAbsolutePercentageError (Mean Absolute Percentage Error, used for regression, dubbed as "MAPE", function name
mape) -
RootMeanSquaredError (Root-Mean-Squared-Error, used for regression.)
-
Accuracy (Accuracy,used for classification, could be represented as a string "Accuracy"; Accuracy=(TP+TN)/(TP+TN+FP+FN); requires ordinal encoding for the inputs
y_trueandy_pred.) -
Precision (Precision, used for binary classification;; Precision = TP/(TP+FP))
-
Recall (Recalling rate, used for binary classification; Recall = TP/(TP+FN))
-
TruePositives (True positives, used for binary classification.)
-
TrueNegatives (True negatives, used for binary classification.)
-
FalsePositives (False positives, used for binary classification.)
-
FalseNegatives (False negatives, used for binary classification.)
-
AUC (Area Under the Curve, represents the area under the ROC curve (TPR vs FPR); it is used for binary classification. An intuitive explanation: pick a positive sample and a negative sample, AUC is the possibility that the prediction of positive sample larger than the prediction of the negative sample.)
-
CategoricalAccuracy (Catigorical Accuracy, same as
Accuracyexcept requiring one-hot encoding for the input labely_true.) -
SparseCategoricalAccuracy (Sparse Categorical Accuracy, same as
Accuracyexcept requiring ordinal encoding for the label y_true.) -
MeanIoU (Intersection-Over-Union, ususally for image segmentation.)
-
TopKCategoricalAccuracy (TopK accuracy for multiple classification, requires one-hot encoding for the input label y_true)
-
SparseTopKCategoricalAccuracy (TopK accuracy for multiple classification, requires ordinary encoding for the input label y_true)
-
Mean (Mean value)
-
Sum (Summation)
2. Customized Metrics#
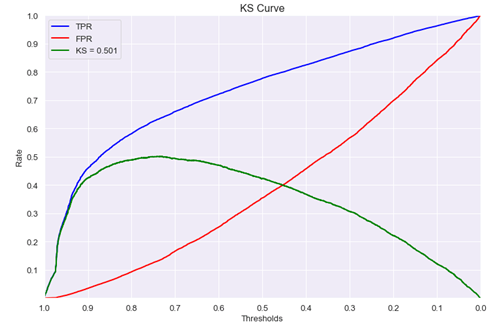
Here we use the K-S (Kolmogorov-Smirnov) statistic, which is frequently used in financial risk management, as an example for the customized metrics.
K-S statistic is used for binary classification problem; KS = max(TPR - FPR), where TPR = TP / (TP + FN), FPR = FP / (FP + TN)
TPR curve is the cumulative distribution function (CDF) of the positive samples, while FPR curve is the CDF of the negative samples.
K-S statistic is the maximum of the difference between the CDF of positive and negative samples.
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras import layers,models,losses,metrics
# Customized metrics defined by function
@tf.function
def ks(y_true,y_pred):
y_true = tf.reshape(y_true,(-1,))
y_pred = tf.reshape(y_pred,(-1,))
length = tf.shape(y_true)[0]
t = tf.math.top_k(y_pred,k = length,sorted = False)
y_pred_sorted = tf.gather(y_pred,t.indices)
y_true_sorted = tf.gather(y_true,t.indices)
cum_positive_ratio = tf.truediv(
tf.cumsum(y_true_sorted),tf.reduce_sum(y_true_sorted))
cum_negative_ratio = tf.truediv(
tf.cumsum(1 - y_true_sorted),tf.reduce_sum(1 - y_true_sorted))
ks_value = tf.reduce_max(tf.abs(cum_positive_ratio - cum_negative_ratio))
return ks_value
y_true = tf.constant([[1],[1],[1],[0],[1],[1],[1],[0],[0],[0],[1],[0],[1],[0]])
y_pred = tf.constant([[0.6],[0.1],[0.4],[0.5],[0.7],[0.7],[0.7],
[0.4],[0.4],[0.5],[0.8],[0.3],[0.5],[0.3]])
tf.print(ks(y_true,y_pred))
0.625
# Customized metrics defined by class
class KS(metrics.Metric):
def __init__(self, name = "ks", **kwargs):
super(KS,self).__init__(name=name,**kwargs)
self.true_positives = self.add_weight(
name = "tp",shape = (101,), initializer = "zeros")
self.false_positives = self.add_weight(
name = "fp",shape = (101,), initializer = "zeros")
@tf.function
def update_state(self,y_true,y_pred):
y_true = tf.cast(tf.reshape(y_true,(-1,)),tf.bool)
y_pred = tf.cast(100*tf.reshape(y_pred,(-1,)),tf.int32)
for i in tf.range(0,tf.shape(y_true)[0]):
if y_true[i]:
self.true_positives[y_pred[i]].assign(
self.true_positives[y_pred[i]]+1.0)
else:
self.false_positives[y_pred[i]].assign(
self.false_positives[y_pred[i]]+1.0)
return (self.true_positives,self.false_positives)
@tf.function
def result(self):
cum_positive_ratio = tf.truediv(
tf.cumsum(self.true_positives),tf.reduce_sum(self.true_positives))
cum_negative_ratio = tf.truediv(
tf.cumsum(self.false_positives),tf.reduce_sum(self.false_positives))
ks_value = tf.reduce_max(tf.abs(cum_positive_ratio - cum_negative_ratio))
return ks_value
y_true = tf.constant([[1],[1],[1],[0],[1],[1],[1],[0],[0],[0],[1],[0],[1],[0]])
y_pred = tf.constant([[0.6],[0.1],[0.4],[0.5],[0.7],[0.7],
[0.7],[0.4],[0.4],[0.5],[0.8],[0.3],[0.5],[0.3]])
myks = KS()
myks.update_state(y_true,y_pred)
tf.print(myks.result())
0.625
Please leave comments in the WeChat official account "Python与算法之美" (Elegance of Python and Algorithms) if you want to communicate with the author about the content. The author will try best to reply given the limited time available.
You are also welcomed to join the group chat with the other readers through replying 加群 (join group) in the WeChat official account.
